
Мы воспользуемся примером набора данных Automobile price data (Raw) (Данные о ценах на автомобили (необработанные)), который доступен в вашем рабочем пространстве.
Посмотрим, как выглядят эти данные. Для этого щелкнули на выходной порт в нижней части набора автомобильных данных и выбрали Visualize.
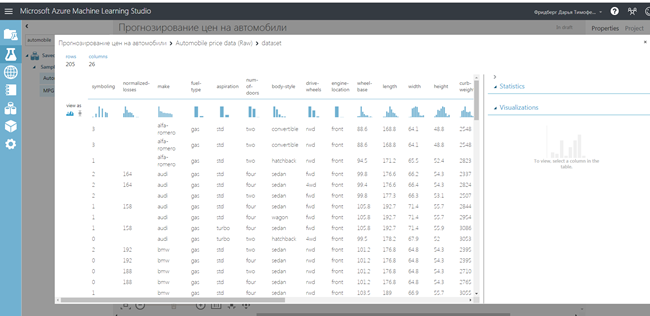
Набор данных обычно требует предварительной обработки, прежде чем он может быть проанализирован. Пропущенные значения необходимо очистить, чтобы модель могла правильно анализировать данные. В нашем случае, мы удалим все строки, содержащие отсутствующие значения. Кроме того, столбец «normalized-losses» имеет большую долю отсутствующих значений, поэтому мы исключим этот столбец из модели.
Сначала мы добавим модуль, который полностью удаляет столбец «normalized-losses», а затем добавим другой модуль, который удаляет любую строку, содержащую отсутствующие данные.
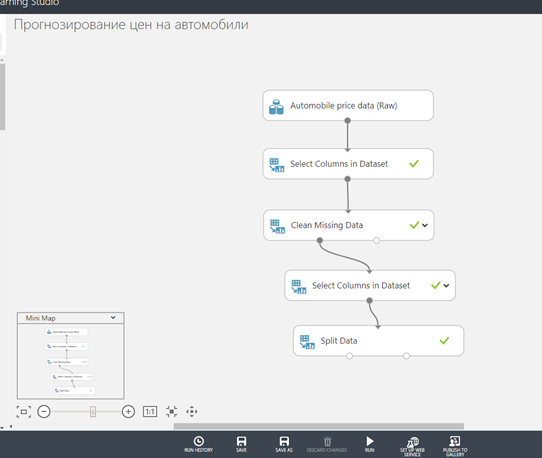
Для этого выберем тип колонок в поле поиска в верхней части палитры модуль найти Select Columns в модуле Dataset module, а затем перетащим его в областьдействия. Этот модуль позволяет нам выбрать, какие столбцы данных мы хотим включить или исключить в модели.
Подключим выходной порт набора данных (Raw) к входному порту модуля Select Columns in Dataset module.
Перетащим модуль Clean Missing Data на холст эксперимента и подключим его к выбранным столбцам в модуле набор данных.

Видим, что больше нет столбцов с пустыми данными, все было сделано верно.
- В поиске выберем Split Data, перетащим на поле и соединим с Select Data Column.
- Нажмем Split Data и выберем. В Properties справа необходимо найти раздел Fraction of rows in the first output dataset. Установим уровень 0,75 (используем 75% для обучения модели и 25% для ее тестирования). Можно использовать другие значения в дальнейшем.
- Для того чтобы выбрать обучающий алгоритм, необходимо пройти следующий путь: Machine Learning => Initialize Model => Regression => Linear Regression. Последний элемент перетаскиваем на поле.
- Выберем в поиске Train Model. Соединим Train Model и Linear Regression образом, показанным на рисунке ниже:
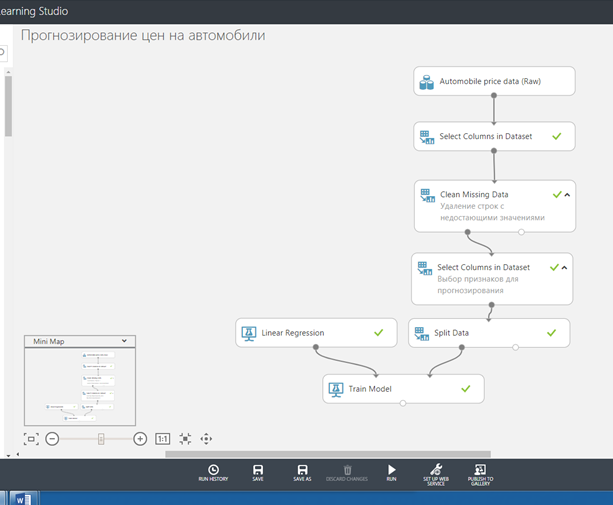
На основании предыдущих шагов мы получили модель, обученную на 75% исходного массива данных. Таким образом, у нас есть оставшиеся 25% массива для того, чтобы проверить на сколько хорошо работает обученная нами модель.
Мы нашли и перетащили модуль «Оценка модели» на поле эксперимента. Соединим выход модуля «Тренировочная модель» на левый входной модуль «Модель оценки». Далее подключаем модуль «Выходные данные» для разделения данных на модуль «Модель оценки».
Далее нам необходимо было вновь запустить эксперимент, и проанализировать результаты, полученные на выходе модуля «Оценка Модели».
На порту вывода будут показаны прогнозируемые значения цены вместе с известными значениями проверочных данных.
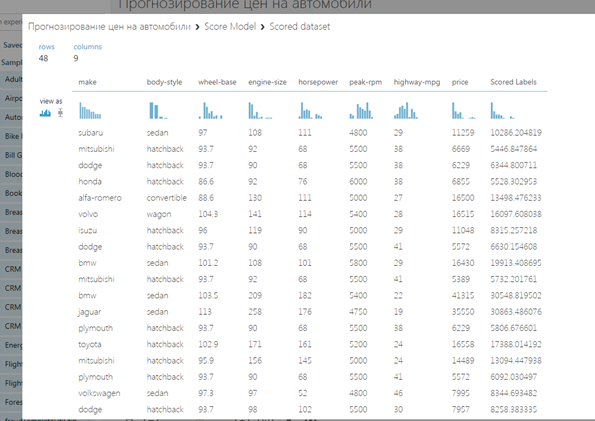
Проверим качество результатов.

- Средняя абсолютная погрешность. Среднее значение абсолютной погрешности (погрешность — это разница между спрогнозированным и фактическим значением).
- Среднеквадратичное отклонение. Квадратный корень из среднего значения возведенных в квадрат арифметических отклонений спрогнозированных значений тестового набора данных.
- Относительное арифметическое отклонение. Среднее арифметическое отклонение по отношению к абсолютной разнице между фактическими значениями и средним арифметическим всех фактических значений.
- Относительное среднеквадратичное отклонение. Среднее арифметическое среднеквадратичных отклонений по отношению к абсолютной разнице между фактическими значениями и средним арифметическим всех фактических значений.
- Коэффициент смешанной корреляции (R в квадрате). Статистический показатель, который оценивает соответствие модели данным.

Оставьте комментарий